Playback Testing
You are modernizing an existing application and are applying the Command Query Responsibility Separation pattern and employing Event Sourcing. You are doing this over a period of time, using the Strangler Application pattern in such a way that there is always a period of coexistence between the old system and the new (refactored) system. Likewise, you are changing underlying data structures and/or switching to new Scalable Stores as part of your refactoring effort.
How do you ensure that the new microservices maintain the same functionality as the old system, especially when the amount of detailed end-to-end application knowledge of the existing application may be limited?
The Strangler pattern always features a period of co-existence between the new and old systems, but one of the unexpected difficulties of this co-existence period occurs just prior to a new microservice going live. One of the basic principles of refactoring (first described in Fowler’s book) is that before you begin any refactoring effort, an essential precondition is that you have a solid set of tests of the existing system that you can also run against the new system. However, when refactoring legacy systems, you cannot assume that this solid set of tests covering all potential code paths exists.
Adequate test coverage cannot be assumed for systems that were not built with detailed unit testing in mind. Automated test tools only became commonly accepted in development in the 1990’s, and Test Driven Development only emerged in the 2000’s, so systems built prior to that often do not have full automated test suites. In many cases, teams do not have the detailed knowledge of the underlying code in order to build adequate unit tests. So it becomes difficult for teams to determine if a refactored system really will respond in the same way as the existing system. What complicates this is that in many cases, even subtle bugs in the existing system have become enshrined in workflows and UI’s - in such a way that they have become hidden or undocumented features rather than bugs.
What is needed is a mechanism for ensuring that the behavior of the new system can be reasonably determined to be “the same” as the old system when a portion of the old system is re-implemented in the new system. Therefore,
Capture live transactions from existing calls over a period of time from the old system as Events. Transform those Events as necessary to match the API of the new system, and then play them back as Events on the new system to ensure that the behavior of the old and new systems match.
There are three issues in implementing an approach like this. The first is capturing the events. If you are following a CQRS approach using Event Sourcing, then one possibility is to capture a set of existing calls to the Write Model, especially if the Write Model is just serving initially as an Adapter Microservice to the existing system. The calls can be wrapped up as Events and then added to the Event Backbone in this case. If there are still calls going to the underlying existing system that do NOT go through the Write Model, then this becomes a little more complicated, as you may need to construct your Events from log messages or other data capture mechanisms.
Once the captured Events have been added to the Event Backbone the next decision is how long a period of time for which you need to capture the events for playback. Often creating a database for these events may be required if playback will cover a longer period than a few hours. In any case, the Events will have to be transformed to the format consumable by the new (refactored) Write Model - if you are capturing them from an adapter-based Write Model, then this is already done for you, but otherwise will be required if you are capturing them from any other source.
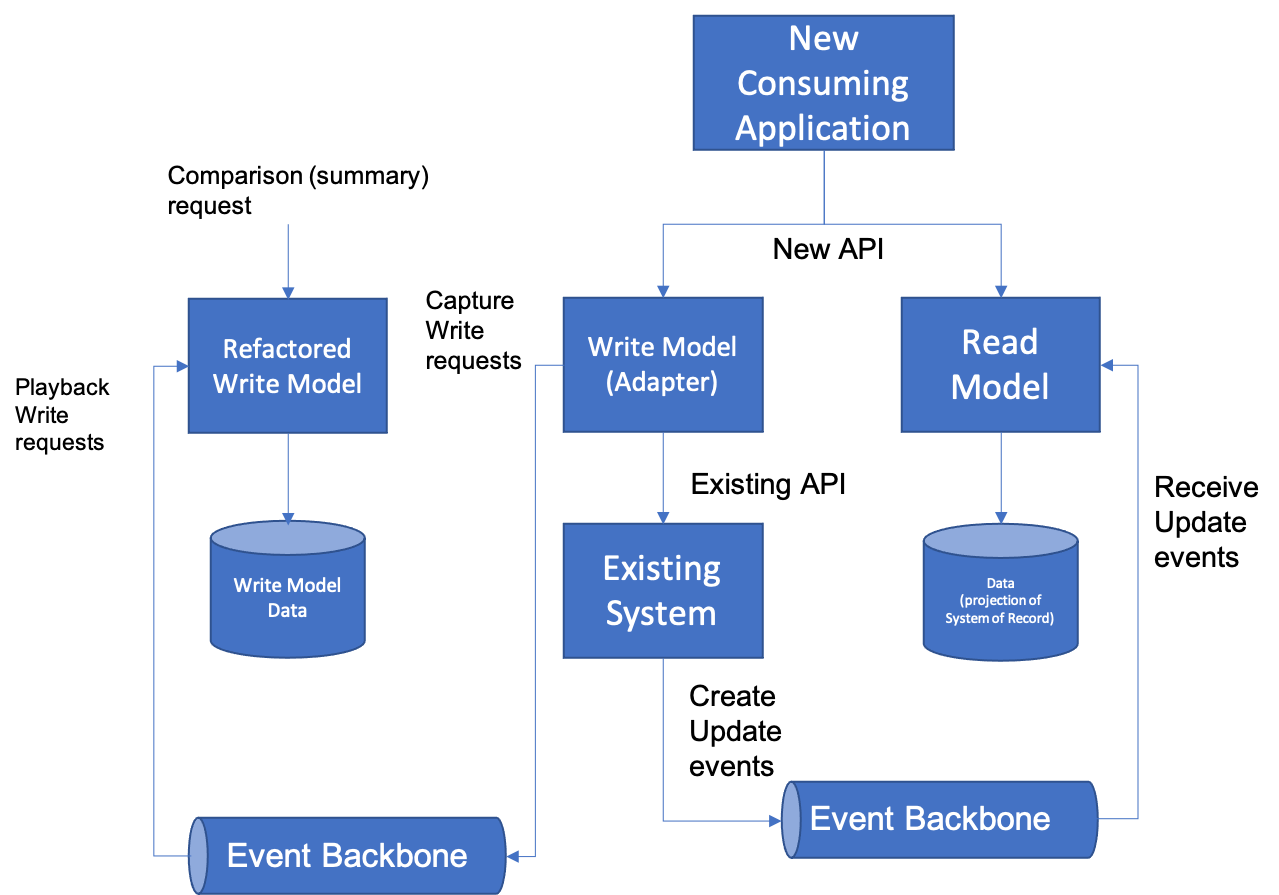
The final stage of this is playing back the captured events on the new (refactored) write model. One key decision to make is then determining how to determine if the state of the new write model reflects the state of the existing system after each transaction is played back and executes. In the simplest case, this can be done at the end of the playback (perhaps comparing summary and total information, by pulling reports, for instance) but in more complex cases, a step-by-step Entity Comparator approach may be required.
The simplest version of this pattern (with capture through adapter-based Write Model and playback comparison through summaries) is shown below:
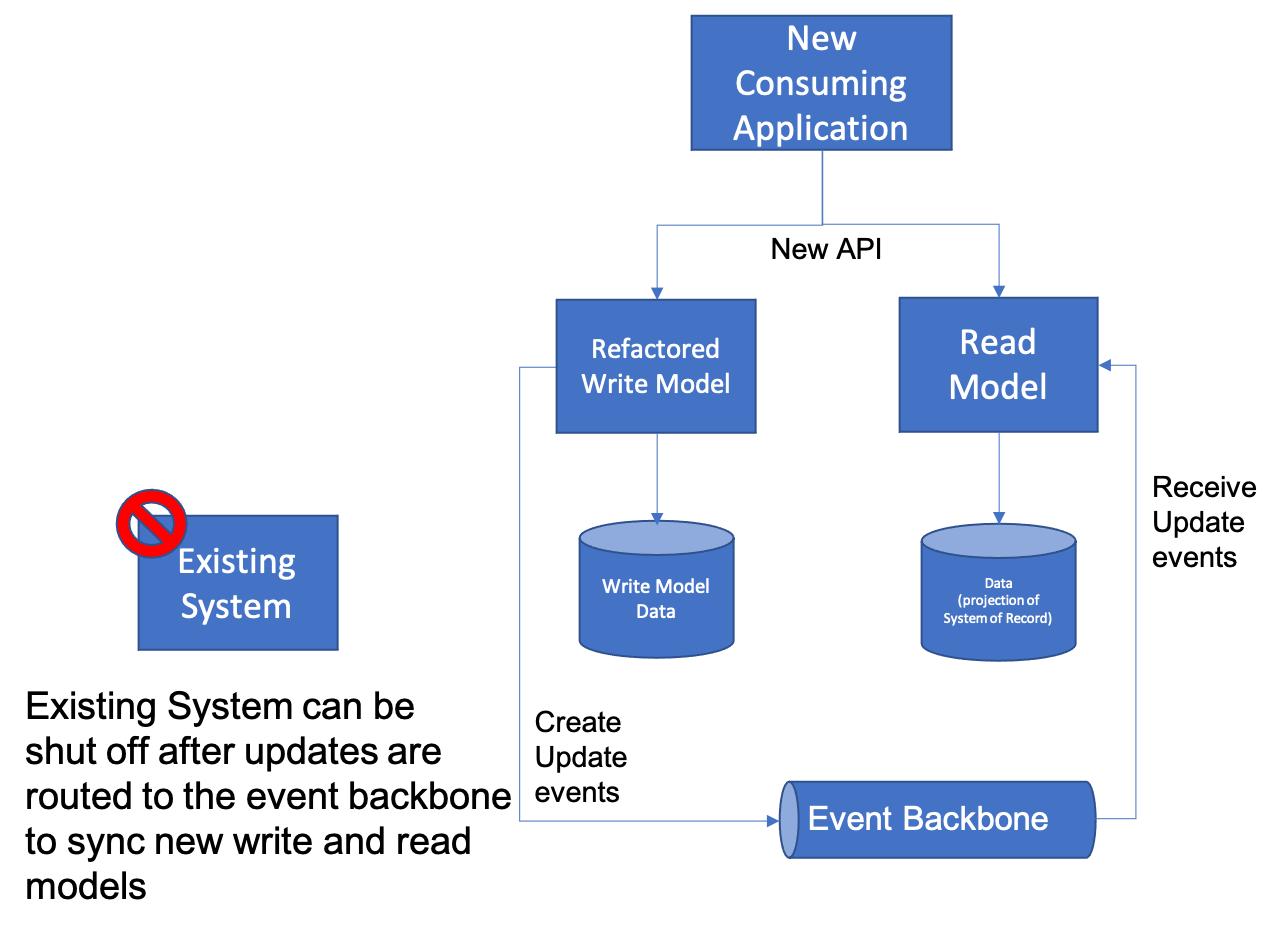
Note that the goal is to complete the Playback Testing successfully so that the existing System can be completely eliminated and replaced with the new (refactored) Write Model as shown below.