Scalable Store Introduction
The cloud has brought a wealth of new options for data storage. Long gone are the days when the only data storage option was an Enterprise relational database for all applications, regardless of whether or not the type of data that was being stored was suited for a table-based representation or not. However, with new choices comes new potential problems. In particular, the non-functional requirements that an Enterprise relational database addressed (resiliancy, backup, performance, security) now become more important, as the number of ways in which these requirements can be addressed increases.
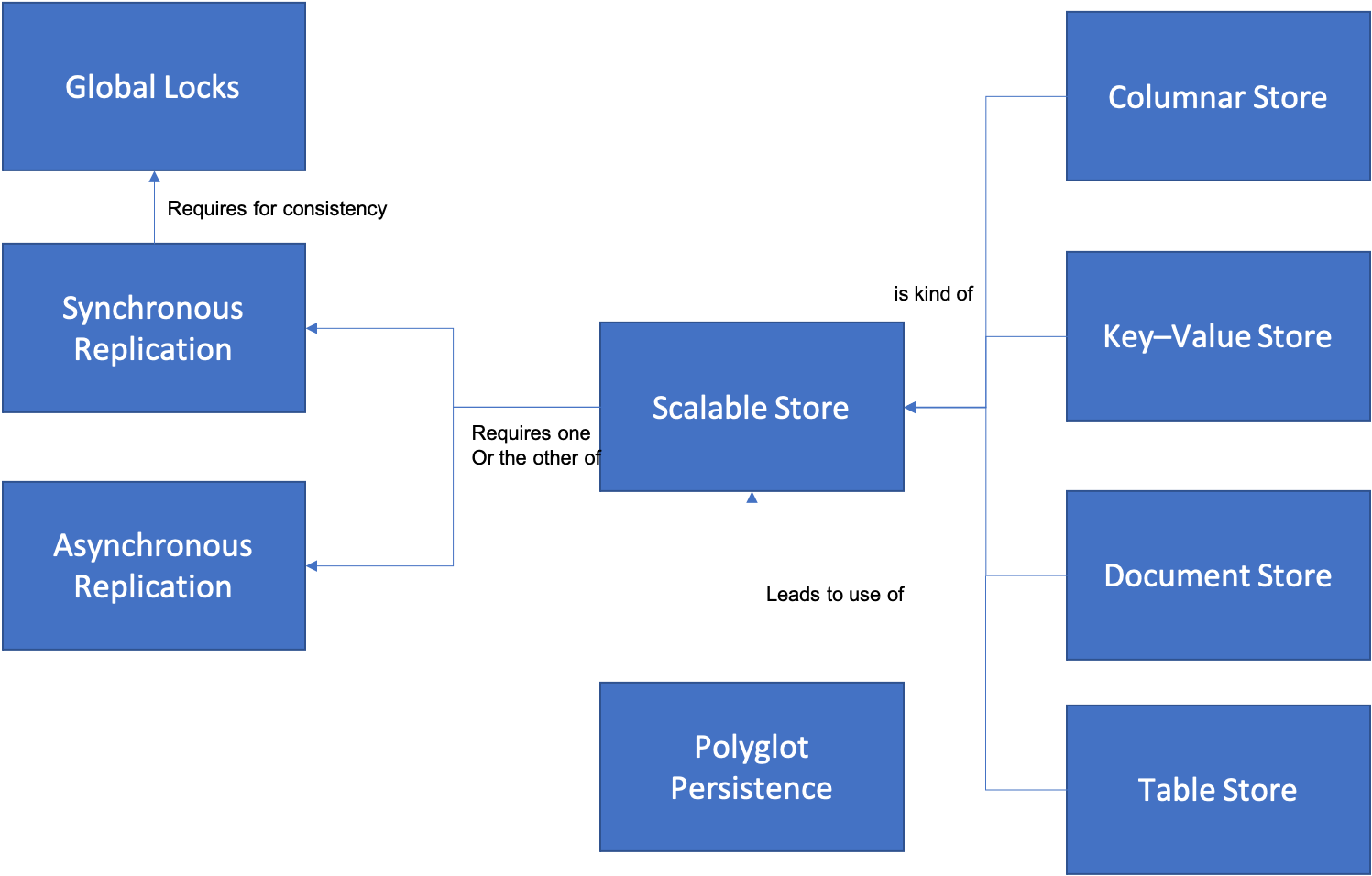
A key part of the microservices architecture is that wherever possible each microservice should control or “own” its own data. However, microservices are also expected to be scalable and stateless. This combination of requirements leads to the need for Scalable Stores, which is the root pattern of this section.
- Scalable Store addresses how to avoid scalability bottlenecks in a microservices architecture by using databases that are naturally distributed and able both to scale horizontally and to survive the failure of any database node.
- Key-Value Store allows you to do simple lookups by acting in principle, like a hash map, with accompanying O(1) performance for many use cases.
- Document Store allows you to store native schemaless JSON data in a database optimized for storing that type of information.
- Table Store recognizes the fact that relational representations are still sometimes the right way to store and manage certain types of application data.
- Columnar Store helps you manage data that is optimized for certain types of queries that commonly occur in Analytics.
- Polyglot Persistence is critical in helping grant teams building microservices the independence to choose the right tool for the job.
Certain architectural concepts are critical to understanding how Scalable Stores scale across multiple datacenters.
- Synchronous Replication is the solution for when data cannot be lost at all, at any time and must be constantly consistent.
- Asynchronous Replication is the solution for other cases - when data should not be lost but may be inconsistent over a period of time.
- Global Locks are required when implementing systems that require consistency of data across multiple datacenters.
The relationships between these patterns is shown in the diagram below: